ID: 34
post_title: Ceph 1st Runthrough
author: ytjohn
post_date: 2017-04-30 21:42:52
post_excerpt: ""
layout: post
permalink: https://new.yourtech.us/?p=34
published: true
These are just some notes I took as I did my first run through on installing Ceph on some spare ECS Hardware I had access to. Note that currently, no one would actually recommend doing this, but it was a good way for me to get started with Ceph.
Installation
Following this guide http://docs.ceph.com/docs/hammer/start/quick-ceph-deploy/
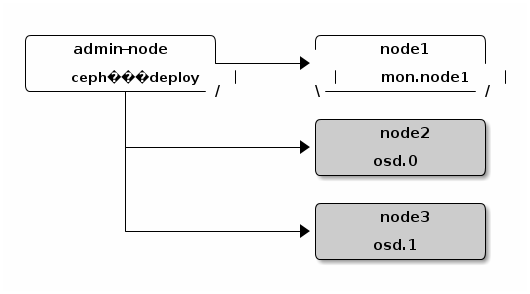
I set this up the first time in the lab, nodes:
- ljb01.osaas.lab (admin-node)
- rain02-r01-01.osaas.lab (mon.node1)
- rain02-r01-03.osaas.lab (osd.0)
- rain02-r01-04.osaas.lab (osd.1)
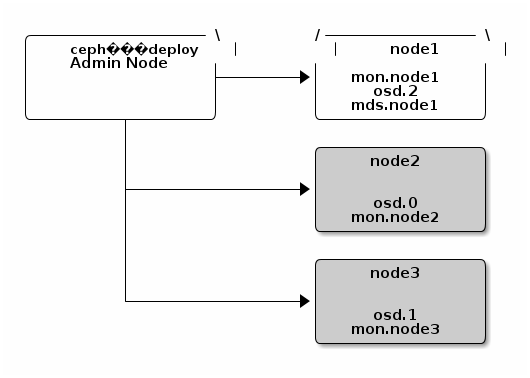
In a more fleshed out setup, I would probably have a dedicated admin node (instead of the jump), and we would start off with the layout like this:
The first 'caveat' was that it tells you to configure a user ("ceph") that can sudo up, which I did. But ceph-deploy attempts to modify the ceph user, which it can't do while ceph is logged in.
[rain02-r01-03][DEBUG ] Setting system user ceph properties..
For step 6, adding OSDs, I diverged again to add disks instead of a directory. http://docs.ceph.com/docs/hammer/rados/deployment/ceph-deploy-osd/
ceph-deploy disk list rain02-r01-01
...
[rain02-r01-01][DEBUG ] /dev/sda :
[rain02-r01-01][DEBUG ] /dev/sda1 other, 21686148-6449-6e6f-744e-656564454649
[rain02-r01-01][DEBUG ] /dev/sda2 other, ext4, mounted on /boot
[rain02-r01-01][DEBUG ] /dev/sdaa other, unknown
[rain02-r01-01][DEBUG ] /dev/sdab other, unknown
[rain02-r01-01][DEBUG ] /dev/sdac other, unknown
[rain02-r01-01][DEBUG ] /dev/sdad other, unknown
[rain02-r01-01][DEBUG ] /dev/sdae other, unknown
I will setup sdaa, sdab, and sdac. Note that while I could use a separate disk partition (like an ssd) to maintain the journal, we only have one ssd in ECS hardware and it hosts the OS. So we'll let each disk maintain its own journal.
ceph-deploy disk zap rain02-r01-01:sdaa # zap the drive
ceph-deploy disk prepare rain02-r01-01:sdaa # format the drive with xfs
ceph-deploy disk activate rain02-r01-01:/dev/sdaa1 # notice we changed to partition path
# /dev/sdaa1 5.5T 34M 5.5T 1% /var/lib/ceph/osd/ceph-0
Repeat those steps for each node and disk you want to activate. Could you imagine doing 32-48 nodes * 60 drives by hand? This seems like a job to be automated.
I also noticed that the drives get numbered sequentially across nodes. I wonder what kind of implications that has for replacing drives or an entire node.
root@rain02-r01-01:~# df -h | grep ceph
/dev/sdaa1 5.5T 36M 5.5T 1% /var/lib/ceph/osd/ceph-0
/dev/sdab1 5.5T 36M 5.5T 1% /var/lib/ceph/osd/ceph-1
/dev/sdac1 5.5T 35M 5.5T 1% /var/lib/ceph/osd/ceph-2
root@rain02-r01-03:~# df -h | grep ceph
/dev/sdaa1 5.5T 35M 5.5T 1% /var/lib/ceph/osd/ceph-3
/dev/sdab1 5.5T 35M 5.5T 1% /var/lib/ceph/osd/ceph-4
/dev/sdac1 5.5T 34M 5.5T 1% /var/lib/ceph/osd/ceph-5
root@rain02-r01-04:~# df -h | grep ceph
/dev/sdaa1 5.5T 34M 5.5T 1% /var/lib/ceph/osd/ceph-6
/dev/sdab1 5.5T 34M 5.5T 1% /var/lib/ceph/osd/ceph-7
/dev/sdac1 5.5T 34M 5.5T 1% /var/lib/ceph/osd/ceph-8
After creating all this, I can do a ceph status.
root@ljb01:/home/ceph/rain-cluster# ceph status
cluster 4ebe7995-6a33-42be-bd4d-20f51d02ae45
health HEALTH_WARN
too few PGs per OSD (14 < min 30)
monmap e1: 1 mons at {rain02-r01-01=172.29.4.148:6789/0}
election epoch 2, quorum 0 rain02-r01-01
osdmap e43: 9 osds: 9 up, 9 in
flags sortbitwise
pgmap v78: 64 pgs, 1 pools, 0 bytes data, 0 objects
306 MB used, 50238 GB / 50238 GB avail
64 active+clean
PG's are known as placement groups. http://docs.ceph.com/docs/master/rados/operations/placement-groups/
That page recommends that for 5-10 OSDs, (I have 9) we set this number to 512. I'm defaulted at 64. But then the tool tells me otherwise.
root@ljb01:/home/ceph/rain-cluster# ceph osd pool get rbd pg_num
pg_num: 64
root@ljb01:/home/ceph/rain-cluster# ceph osd pool set rbd pg_num 512
Error E2BIG: specified pg_num 512 is too large (creating 448 new PGs on ~9 OSDs exceeds per-OSD max of 32)
I'll put this down as a question for later and set it to 128.
This does nothing, so I learned what I really need to do is make more pools. I make a new pool, but my HEALTH_WARN has changed to reflect my mistake.
root@ljb01:/home/ceph/rain-cluster# ceph status
cluster 4ebe7995-6a33-42be-bd4d-20f51d02ae45
health HEALTH_WARN
pool rbd pg_num 128 > pgp_num 64
monmap e1: 1 mons at {rain02-r01-01=172.29.4.148:6789/0}
election epoch 2, quorum 0 rain02-r01-01
osdmap e48: 9 osds: 9 up, 9 in
flags sortbitwise
pgmap v90: 256 pgs, 2 pools, 0 bytes data, 0 objects
311 MB used, 50238 GB / 50238 GB avail
256 active+clean
There is also a pgp_num to set, so I set that to 128. Now everything is happy and healthy. And I've only jumped from 306MB to 308MB used.
root@ljb01:/home/ceph/rain-cluster# ceph status
cluster 4ebe7995-6a33-42be-bd4d-20f51d02ae45
health HEALTH_OK
monmap e1: 1 mons at {rain02-r01-01=172.29.4.148:6789/0}
election epoch 2, quorum 0 rain02-r01-01
osdmap e50: 9 osds: 9 up, 9 in
flags sortbitwise
pgmap v100: 256 pgs, 2 pools, 0 bytes data, 0 objects
308 MB used, 50238 GB / 50238 GB avail
256 active+clean
Placing Objects
You can place objects into pools with rados command.
root@ljb01:/home/ceph/rain-cluster# echo bogart > testfile.txt
root@ljb01:/home/ceph/rain-cluster# rados put test-object-1 testfile.txt --pool=pool2
root@ljb01:/home/ceph/rain-cluster# rados -p pool2 ls
test-object-1
root@ljb01:/home/ceph/rain-cluster# ceph osd map pool2 test-object-1
osdmap e59 pool 'pool2' (1) object 'test-object-1' -> pg 1.74dc35e2 (1.62) -> up ([8,5], p8) acting ([8,5], p8)
Object Storage Gateway
Ceph does not provide a quick way to install and configure object storage gateways. You essentially have to install apache, libapache2-mod-fastcgi, rados, radosgw, and create a virtualhost. While you could do this on only a portion of your OSD nodes, it seems like it would make most sense to do it on each OSD node so that each node can be part of the pool.
http://docs.ceph.com/docs/hammer/install/install-ceph-gateway/
Repo change:
http://gitbuilder.ceph.com/apache2-deb-$(lsb_release -sc)-x86_64-basic/ref/master
should be:
http://gitbuilder.ceph.com/ceph-deb-$(lsb_release -sc)-x86_64-basic/ref/master
After installing the packages, you need to start configuring. http://docs.ceph.com/docs/hammer/radosgw/config/
After steps 1-5 (creating and distributing a key), you need to make a storagepool.
root@ljb01:/home/ceph/rain-cluster# ceph osd pool create storagepool1 128 128 erasure default
pool 'storagepool1' created
Creating domain "*.rain.osaas.lab" for this instance. I also had to create /var/log/radosgw before I could start the radosgw service.
After starting radosgw, I had to chown the fastcgi.sock file ownership:
chown www-data:www-data /var/run/ceph/ceph.radosgw.gateway.fastcgi.sock
Next, you go to the admin section to create users.
root@rain02-r01-01:/var/www/html# radosgw-admin user create --uid=john --display-name="John Hogenmiller" [email protected]
{
"user_id": "john",
"display_name": "John Hogenmiller",
"email": "[email protected]",
"max_buckets": 1000,
"keys": [
{
"user": "john",
"access_key": "KH6ABIYU7P1AC34F9FVC",
"secret_key": "OFjRqeMGH26yYX9ggxr8dTyz9KYZMLFK9W5i1ACV"
}
],
"temp_url_keys": []
}
Or specify a key like we do in other environments.
root@rain02-r01-01:/var/www/html# radosgw-admin user create --uid=cicduser1 --display-name="TC cicduser1" --access-key=cicduser1 --secret-key='5Y4pjcKhjAsmbeO347RpyaVyT6QhV8UHYc5YWaBB'
{
"user_id": "cicduser",
"display_name": "TC cicduser1",
"keys": [
{
"user": "cicduser1",
"access_key": "cicduser1",
"secret_key": "5Y4pjcKhjAsmbeO347RpyaVyT6QhV8UHYc5YWaBB"
}
]
}
Fun fact: You can set quotas and read/write capabilities on users. It also can do usage statistics for a given time period.
All of the CLI commands can be implemented over API: http://docs.ceph.com/docs/hammer/radosgw/adminops/ - in this, just adding /admin/
(configurable) to the url. You can give any S3 user admin capabilities. It's the same backend authentication for both.
I also confirmed that by installing radosgw on a second node, all user ids and bucket was still available. Clustering confirmed.
Automation
When it comes to automating this, there are several options.
Build our own ceph-formula up into something that fully manages ceph.
Pros
- It will do what we want it to.
Cons
- Our current ceph-formula currently only installs packages.
- Lots of work involved
Refactor public ceph-salt formula to meet our needs.
https://github.com/komljen/ceph-salt
Pros:
- ceph-salt seems to cover most elements, including orcehstration
- uses a global_variables.jinja much like we use map.jinja
Cons
- I'm sure we'll find something wrong with it. (big grin)
- maintained by 1 person
- last updated over a year ago
Use Kolla to setup Ceph:
http://docs.openstack.org/developer/kolla/ceph-guide.html
Pros:
* Openstack team might be using Kolla - standardization
* Already well built out
* Puts ceph components into docker containers (though some might consider this a con)
Cons:
- It's reported that it work primarily on Redhat/Centos; less so on Ubuntu
- Uses ansible as underlying management - this introduces a secondary management system over ssh
- Is heavily opinionated based on Openstack architecture (some might say this is a pro)
Use Ansible-Ceph:
https://github.com/ceph/ceph-ansible
Pros:
- Already well built out
- Highly flexible/configurable
- Works on Ubuntu
- Not opinionated
- maintained by ceph project
- large contribution base
Cons:
- Uses ansible as underlying management - this introduces a secondary management system (in additon to salt) over ssh